
 推荐文章
推荐文章


Copyright 2025 HNCloud Limited.
香港联合通讯国际有限公司
解决deepseek服务器繁忙的方法本地化部署
时间 : 2025-02-18 10:38:10
编辑 : 华纳云
阅读量 : 322
DeepSeek作为一款开源的模型从上线起就备受关注,不仅拥有强大的自然语言处理能力,还能够辅助写代码。但随着用户的访问量激增,deepseek服务器繁忙问题频繁出现,给使用者带来了一些不便。但是开发者通过本地化部署可以很好的解决这个问题。下面是deepseek服务器本地化部署的步骤和方法。
一、安装 Ollama
要在本地运行 DeepSeek,我们需要使用 Ollama——一个开源的本地大模型运行工具。
首先,访问 Ollama官网 下载该工具。官网提供了针对不同操作系统的安装包,用户只需选择适合自己电脑的版本即可。在本例中,我们选择下载适用于 Windows 操作系统的版本。
Ollama 安装包下载后双击install,安装速度还是比较快的,
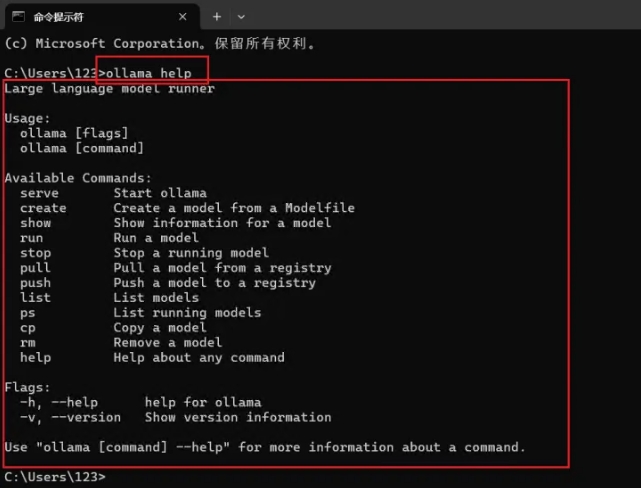
安装完成 Ollama 后,打开电脑的 CMD(命令提示符)。只需在电脑下方的搜索框中输入“cmd”并按回车,即可打开命令提示符窗口。输入【ollama help】
二、下载部署 Deepseek 模型
返回 Ollama官网 ,在网页上方的搜索框中输入 “DeepSeek-R1”,这是我们要在本地部署的模型。
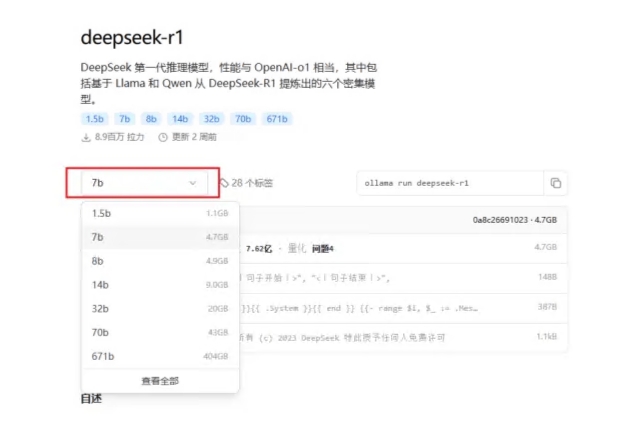
点击 “DeepSeek-R1” 后,您将进入模型的详情页面,页面中会显示多个可选择的参数规模。每个参数规模代表了模型的不同大小和计算能力,从 1.5B 到 671B 不等。这里的 “B” 代表 “Billion”,即“十亿”,因此:
● 1.5B 表示该模型具有 15 亿个参数,适合轻量级任务或资源有限的设备使用。
● 671B 则代表该模型拥有 6710 亿个参数,模型规模和计算能力都极为强大,适合大规模数据处理和高精度任务,但对硬件要求也相应更高。
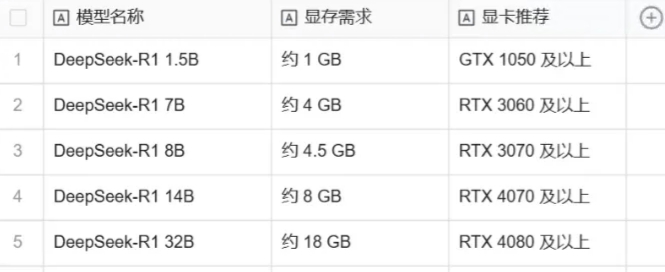
选择不同的参数规模意味着你可以根据自己的硬件配置和应用需求,决定使用哪个版本的模型。较小的模型需要的计算资源较少,适合快速推理或硬件资源较弱的设备;而较大的模型则在处理复杂任务时具有更高的推理能力,但需要更多的内存和显存支持。
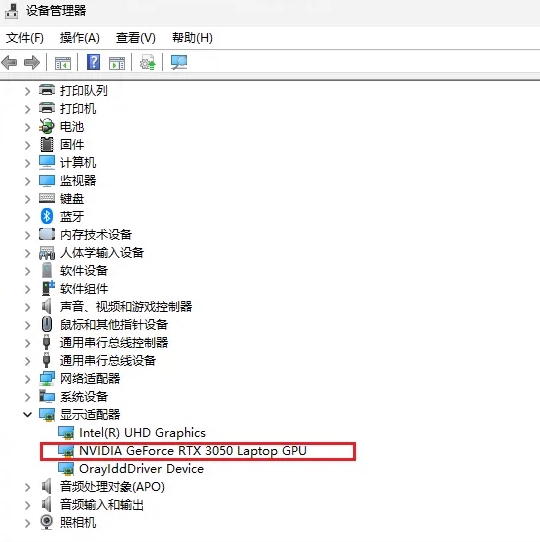
按下Win + X组合键或搜索“设备管理器”,展开“显示适配器”类别,可以看到已安装的显卡型号。如果需要更详细的信息,可以右键点击显卡名称,选择“属性”查看详细信息。我的是【RTX 3050】稳妥点下载1.5B
选择好模型规模后,复制右边的一个命令。【ollama run deepseek-r1:1.5b】
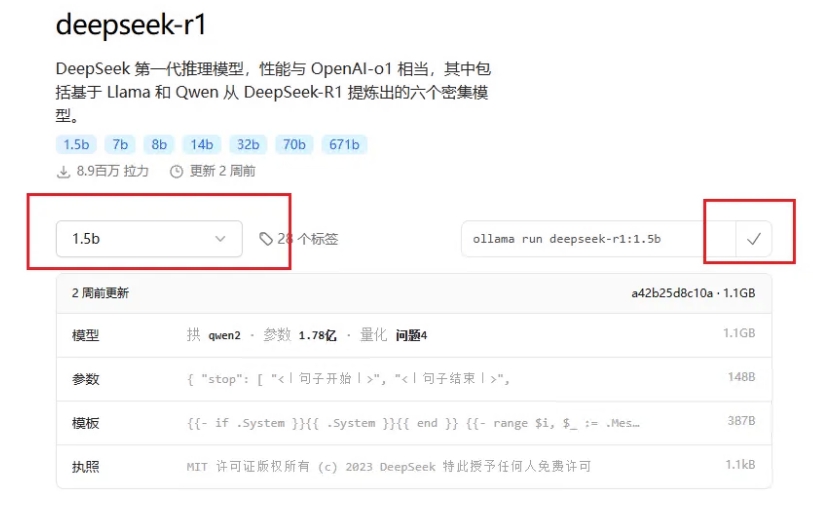
复制命令后,回到命令提示符窗口,将刚刚复制的命令粘贴进去,并按回车键即可开始下载模型。【下载大概1小时左右,有点慢】
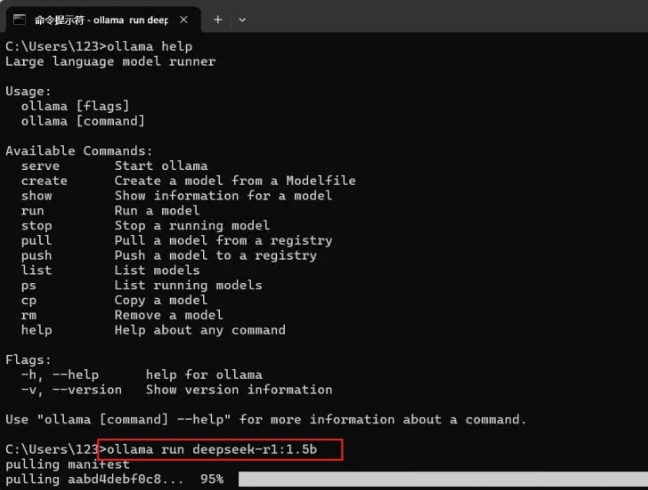
模型下载完成后,您可以直接在命令提示符窗口中使用它,开始进行推理操作。
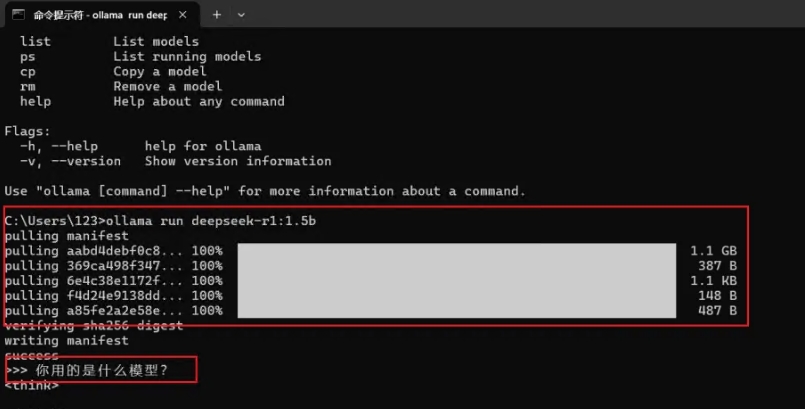
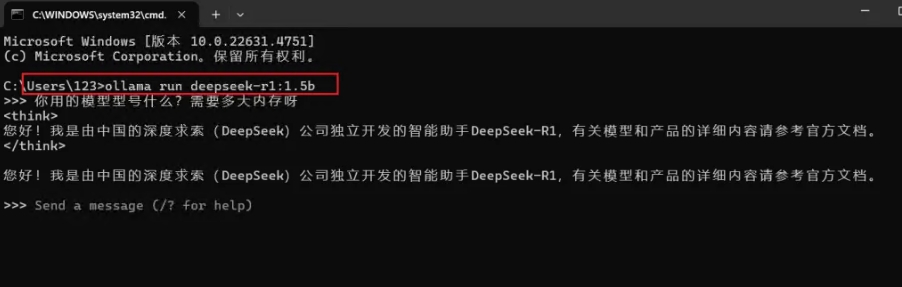
以后如果我们需要再次使用 DeepSeek 模型,只需打开命令提示符窗口,直接输入之前复制的指令,按回车即可重新启动模型并进行推理操作。【ollama run deepseek-r1:1.5b】(1.5b有点不够智能,模型数量不够)
三、可视化图文交互界面 Chatbox
虽然我们可以在本地使用 DeepSeek 模型,但其默认的命令行界面较为简陋,很多用户可能不太习惯。为了提供更直观的交互体验,我们可以使用 Chatbox 这个可视化的图文界面来与 DeepSeek 进行交互。
只需访问 Chatbox 官网,在这里,你可以选择使用其本地客户端,或者直接通过网页版进行操作,享受更友好的使用体验。
进入 Chatbox 网页版本后,点击“使用自己的 API Key 或本地模型”选项。这将允许你连接到自己本地的 DeepSeek 模型或通过 API Key 访问外部服务。
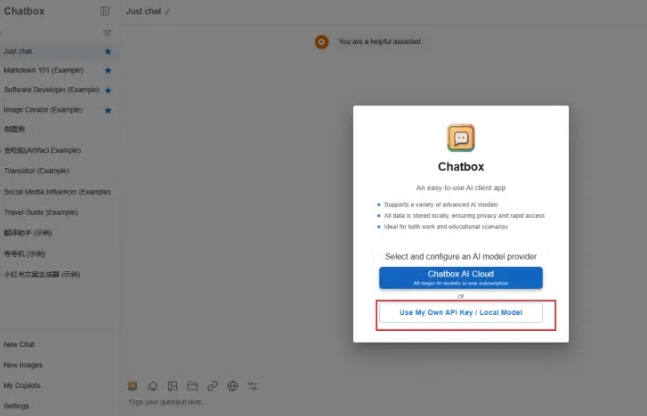
这里需要注意的是,为了能够 Ollama 能远程链接,根据教程操作一下。一般无需配置;
如果你使用的是 window的PC应用【pc端下载过程不展示了下载就行】
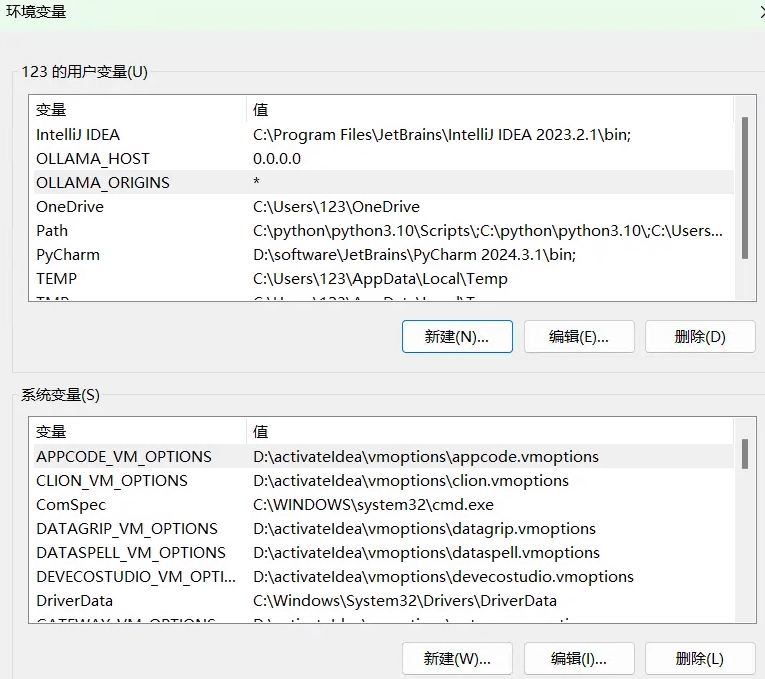
只需要配置相应的环境变量即可。配置好环境变量后,需要重启 Ollama 程序以使设置生效。
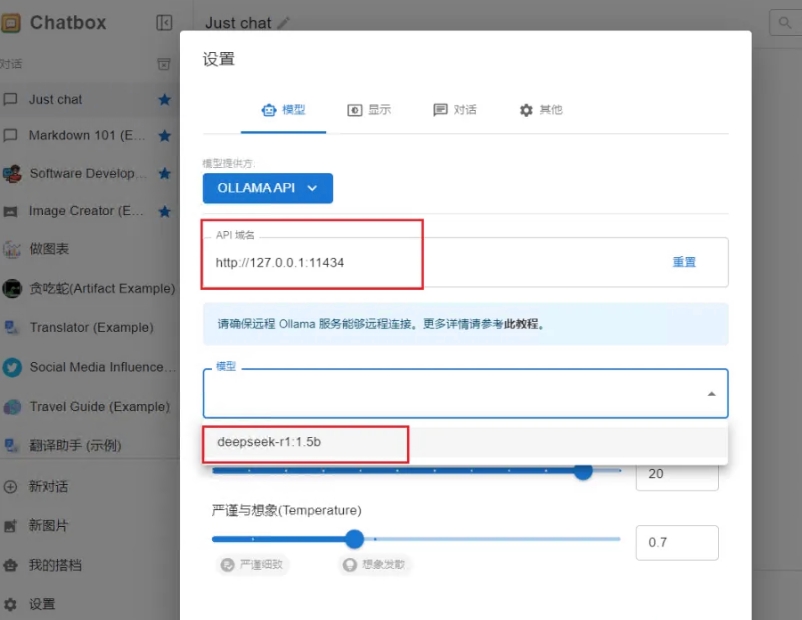
重启 Ollama 程序后,返回到 Chatbox 设置界面,关闭当前的设置窗口,然后重新打开它。在重新打开后,你就能在界面中选择已经部署好的 DeepSeek 模型了。选择模型后,点击保存即可开始使用。
接下来,只需在 Chatbox 中新建对话即可开始使用 DeepSeek 模型。以下图为例,您可以看到上方是模型的思考过程,下方则是模型给出的答案。
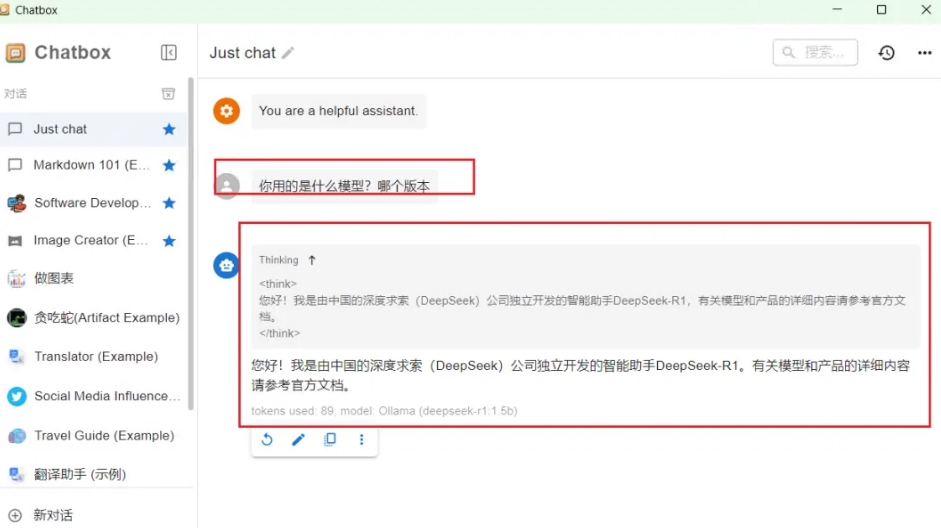
总的来说,本地部署不仅是解决DeepSeek服务器响应慢和系统宕机问题的有效方法,还为用户提供了更加稳定、便捷的使用体验。如果你也在使用DeepSeek,或者正在考虑部署类似的模型,按照这篇指南进行操作,将会大大提升你的工作效率,告别频繁的宕机和不稳定的服务,带来更顺畅的体验。

